I am a first-year Ph.D. student at MIT EECS, advised by Prof. Song Han.
Previously, I received my B.Eng. in Computer Science from Shanghai Jiao Tong University (ACM Honors Class). During my junior year, I also had a wonderful time as an undergraduate researcher advised by Prof. Jingwen Leng at SJTU EPCC Lab.
My research interests lie in Efficient Algorithms and Systems for Large Language Models.
News
Publications
* indicates equal contribution
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang*,
Yilong Zhao*,
Kan Zhu,
Guangxuan Xiao,
Baris Kasikci,
and Song Han
ICML 2024
/ Abstract
/ Code
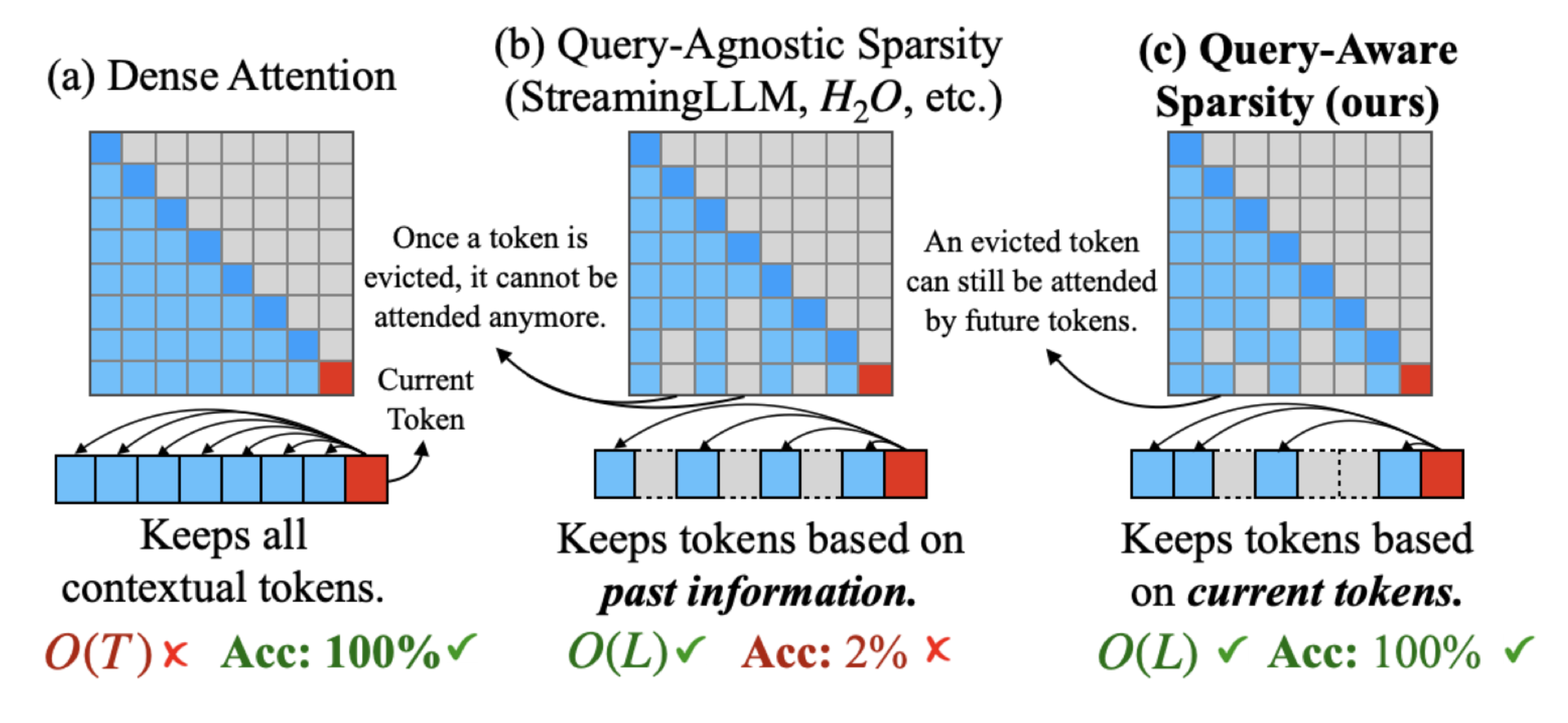
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss.
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Ji Lin*,
Jiaming Tang*,
Haotian Tang,
Shang Yang,
Wei-ming Chen,
Wei-chen Wang,
Guangxuan Xiao,
Xingyu Dang,
Chuang Gan,
and Song Han
MLSys 2024
/ Best Paper Award
/ Abstract
/ Code
Large language models (LLMs) have shown excellent performance on various tasks, but the astronomical model size raises the hardware barrier for serving (memory size) and slows down token generation (memory bandwidth). In this paper, we propose Activation-aware Weight Quantization (AWQ), a hardwarefriendly approach for LLM low-bit weight-only quantization. Our method is based on the observation that weights are not equally important: protecting only 1% of salient weights can greatly reduce quantization error. We then propose to search for the optimal per-channel scaling that protects the salient weights by observing the activation, not weights. AWQ does not rely on any backpropagation or reconstruction, so it can well preserve LLMs’ generalization ability on different domains and modalities, without overfitting to the calibration set; it also does not rely on any data layout reordering, maintaining the hardware efficiency. AWQ outperforms existing work on various language modeling, common sense QA, and domain-specific benchmarks. Thanks to better generalization, it achieves excellent quantization performance for instruction-tuned LMs and, for the first time, multimodal LMs. We also implement efficient tensor core kernels with reorder-free online dequantization to accelerate AWQ, achieving a 1.45x speedup over GPTQ and is 1.85x faster than the cuBLAS FP16 implementation. Our method provides a turn-key solution to compress LLMs to 3/4 bits for efficient deployment.
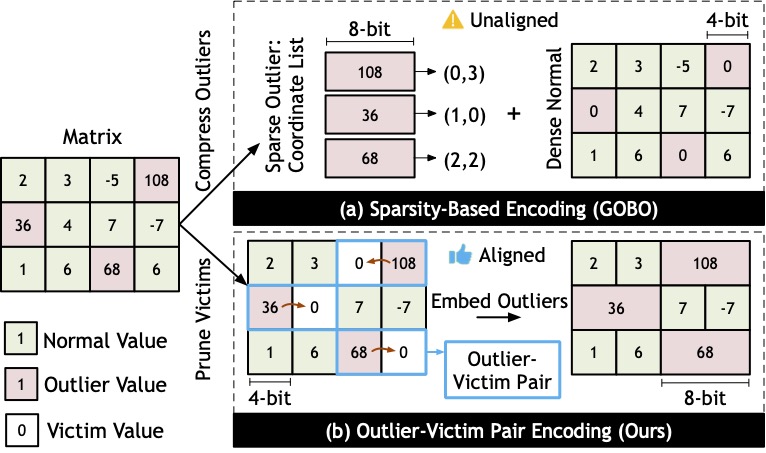
OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization
Cong Guo*,
Jiaming Tang*,
Weiming Hu,
Jingwen Leng,
Chen Zhang,
Fan Yang,
Yunxin Liu,
Minyi Guo,
and Yuhao Zhu
ISCA 2023
/ Abstract
/ Code
We propose OliVe, an algorithm/architecture co-designed solution that adopts an outlier-victim pair (OVP) quantization, which can handle outlier values locally with low hardware overheads and can achieve high performance gains. The key insight of OliVe is that outliers are important while the normal values next to them are not. Thus those normal values (called victims) can be sacrificed to accommodate outliers. This enables a memory-aligned OVP encoding scheme, which can be efficiently integrated to the existing hardware accelerators like systolic array and tensor core. As a result, OliVe-based accelerator surpasses the existing outlier-aware accelerator, GOBO, by 4.5x speedup and 4.0x energy reduction, respectively, with a superior model accuracy.


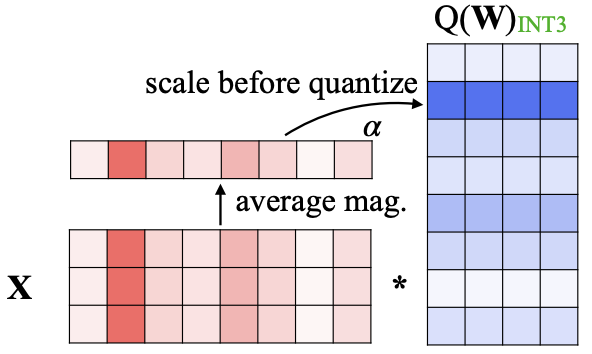 AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration MLSys 2024 / Best Paper Award / Abstract / Code
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration MLSys 2024 / Best Paper Award / Abstract / Code